CODE RED Postmortem: API Green, UI Dead (UI Reliability Incident)
A blameless postmortem of a CODE RED incident where APIs returned 200 but the UI was non-interactive...
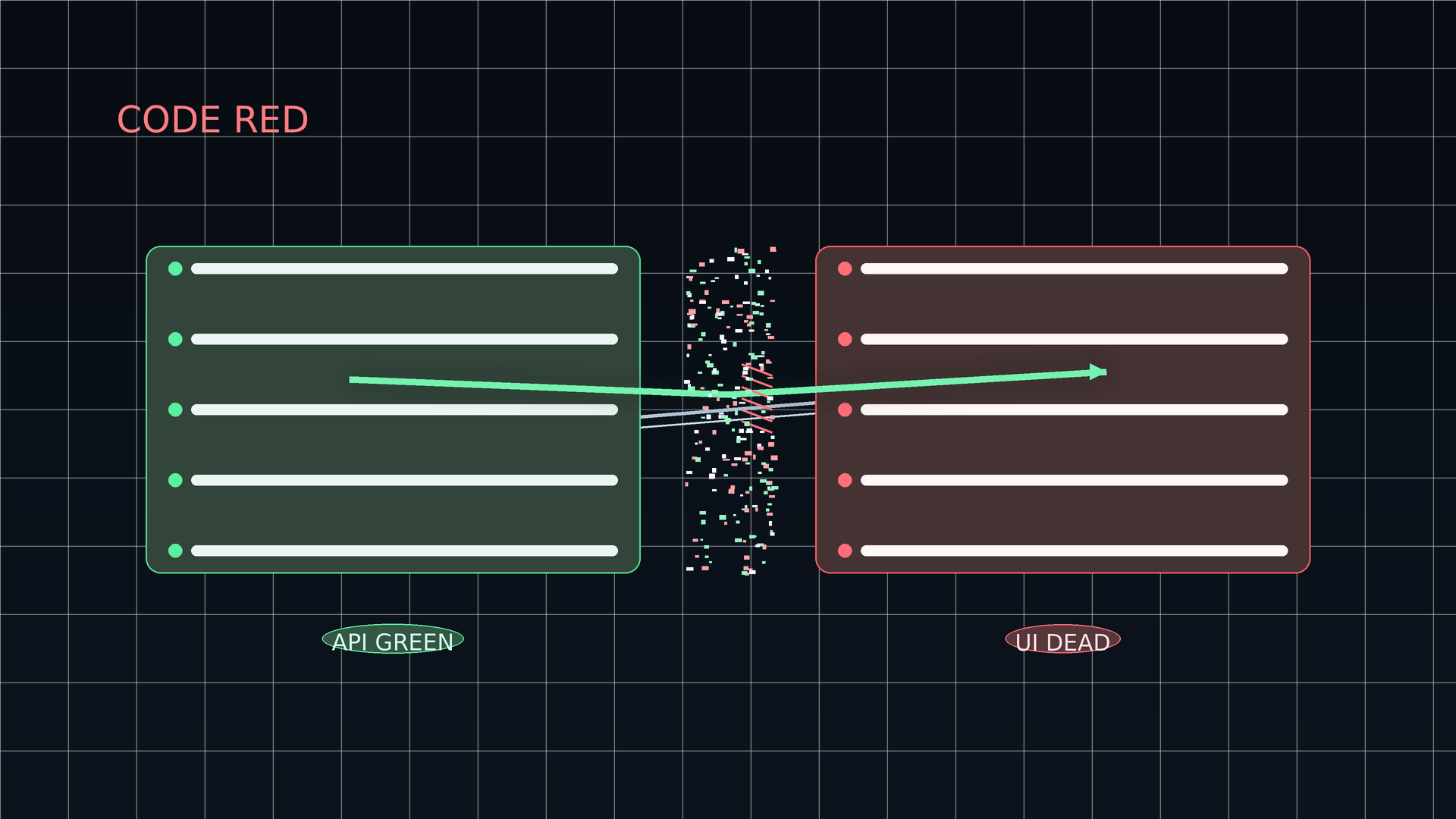
CODE RED: When “API Green” Still Means the Product Is Down
February 24, 2026
Executive summary
We declared CODE RED after users reported that the product looked “up” (requests returned 200) but was effectively unusable: the UI loaded yet was non-interactive. In short: API green, UI dead.
This incident wasn’t caused by an outage of any single backend dependency. It was an orchestration and reliability failure across the release surface—frontend behavior, API contract coverage, routing/build identity, and database schema alignment. Our monitoring and release gates were biased toward “server is responding” rather than “a user can complete a basic workflow.”
We mitigated quickly, restored interactivity, and then implemented corrective actions to prevent this class of failure: a single source of truth (SSOT) rollout checklist with escalation, UI smoke tests (Playwright) as a deploy gate, build identity checks to prevent stale/wrong-route deployments, CSP and UI alignment, schema migration discipline, and backwards-compatible workflow writes. The release proceeded to GO only after gates passed.
Customer impact
What users experienced
- The application UI rendered but key controls did not respond to clicks/keyboard input.
- Core flows (e.g., navigating the dashboard, creating projects, triggering workflows) failed or silently did nothing.
What operators saw
- API endpoints returned
200and basic uptime checks looked healthy. - Some client-side actions never reached the API due to blocked handlers and UI-layer interception.
- Where requests did reach the backend, some failed due to missing contracts or schema drift.
Duration
- The user-visible window spanned a portion of the release/rollout cycle until we reverted/patch-fixed and revalidated. (Exact timestamps omitted intentionally; the remediation sequence below captures the order of events.)
Detection & escalation
We detected the issue through a mix of user reports and internal verification. Our standard backend-oriented dashboards did not trigger an immediate alarm because they were optimized for latency/error-rate and “can the server respond,” not “can a user complete an interaction.”
Once confirmed, we escalated to CODE RED because:
- The UI being non-interactive is equivalent to a full outage for most users.
- The “API green” signal created a false sense of safety and risked prolonging time-to-mitigation.
What happened (high-level)
Several independent issues overlapped in a way that produced the same symptom: a UI that looked loaded but behaved like it was frozen.
1) CSP blocked inline event handlers (script-src-attr)
A Content Security Policy setting blocked inline script attributes (e.g., inline onClick/handler patterns or frameworks compiling to attribute-bound handlers). The UI could render HTML/CSS, but user interactions were prevented from executing expected client-side logic. This is the classic “everything looks normal until you try to click.”
Why it mattered: our health checks validated the server response and page load, not interactive behavior.
2) Missing API contracts (notably POST /projects)
Some UI flows depended on an API contract that was absent or not deployed/registered as expected. As a result, even when the UI attempted to proceed, it could not successfully complete the underlying action.
Why it mattered: incomplete contract coverage turns UI interactions into no-ops or failures that can be masked by generic 200 responses elsewhere.
3) Stale build / wrong route for the dashboard
A routing/build identity mismatch meant the deployed frontend did not correspond to the intended version (or served the wrong route bundle for the dashboard). In practice, users received a UI shell that didn’t line up with the backend and feature expectations.
Why it mattered: “it deployed” is not the same as “the correct artifact is serving the correct route.”
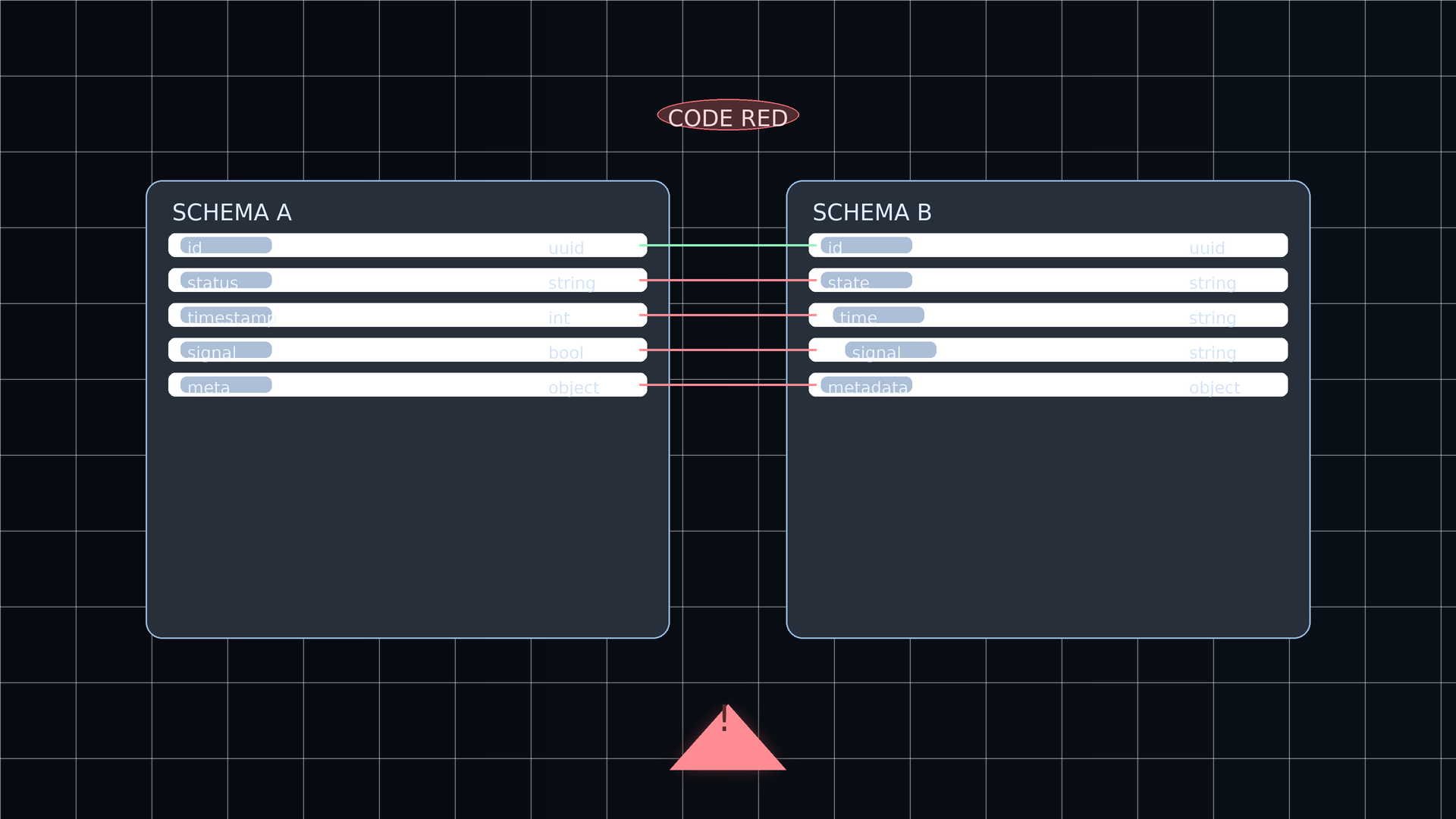
4) Schema drift: workflows insert expected org_id that didn’t exist in DB
A backend write path attempted to insert workflow records including org_id, but the database schema in the target environment did not contain that column. This caused failures for workflow-related actions even when the UI and API routing were otherwise correct.
Why it mattered: schema mismatches are orchestration failures; they don’t always show up as obvious “service down” signals, and can hide behind retries or partial successes.
5) UI overlay intercept broke automation and user clicks
An overlay layer (intended for layout, loading, or modal behavior) intercepted pointer events. This prevented clicks from reaching the underlying controls and also interfered with automation attempts used to validate the UI.
Why it mattered: overlays can create a product-wide “dead UI” symptom even while everything else appears operational.
Timeline (sanitized, sequence-focused)
- T0: Reports of non-responsive UI; basic API health appears normal.
- T0 +: On-call reproduces: UI loads, clicks don’t trigger expected actions.
- T0 +: Investigation identifies multiple contributing factors, starting with client-side policy/interaction issues.
- T0 +: Mitigation applied to restore interactivity and align UI/runtime behavior.
- T0 +: Follow-on fixes address API contract completeness, build/route correctness, and schema alignment.
- T0 +: We introduce and/or enforce new release gates (UI smoke + artifact identity) before proceeding.
- GO: Release state returned to green only after interactive checks and gates passed.
Root cause analysis (blameless)
This incident was caused by gaps between what we were measuring and what users needed, amplified by cross-layer coupling:
- Monitoring gap: We treated
200responses and page availability as a proxy for usability. - Release surface gap: Frontend policy (CSP) and UI layering can break interactivity without “breaking the server.”
- Contract gap: UI-driven features require explicit, versioned API contracts; missing endpoints are reliability risks.
- Artifact/route gap: Without build identity checks, a stale or misrouted bundle can ship silently.
- Migration gap: Schema drift is a deployment coordination issue; write paths must be compatible with the deployed schema.
No single change “caused” everything; this was a reliability failure that emerged from multiple small mismatches landing together.
What we changed (fixes & prevention)
1) SSOT rollout doc + escalation path
We created/updated a single source of truth rollout document that defines:
- required verification steps (including UI interactivity),
- ownership and escalation,
- “stop-the-line” criteria for CODE RED.
This reduces ambiguity during high-pressure rollouts.
2) UI smoke gate (Playwright) as a deploy gate
We implemented a Playwright-based smoke test that must pass before a rollout proceeds. The smoke focuses on user outcomes, not just network status:
- page loads,
- primary navigation works,
- a basic create/read action works,
- no overlay blocks primary controls,
- critical console/CSP violations are flagged.
3) Build identity checks
We added checks to ensure:
- the deployed artifact matches the expected build ID/version,
- the dashboard route serves the correct bundle,
- cache/stale deployment conditions are detectable.
4) CSP/UI alignment
We aligned CSP settings with the UI’s runtime behavior:
- removed accidental blocks that prevented legitimate interaction code,
- ensured policy changes are tested in the same way as functional changes.
5) Schema migration discipline
We tightened migration practices so schema changes are:
- applied in the correct order,
- verified in pre-prod with the same gates,
- paired with rollback-safe behavior where possible.
6) Backwards-compatible workflow insert
We updated the workflow write path to remain compatible across schema versions—so that inserts won’t fail if a column is absent, and can safely evolve as the schema rolls forward.
Lessons learned
- “API green” is not “product up.” Reliability must include UX-level checks.
- Frontend policies can be availability risks. CSP and UI layering deserve the same rigor as backend changes.
- Contracts are part of uptime. Missing endpoints are outages for the features that depend on them.
- Artifact correctness is a first-class gate. Shipping the wrong bundle is functionally equivalent to shipping a broken feature.
- Schema evolution must be coordinated. Backwards compatibility and migration order prevent avoidable failures.
Current status
We returned to GO with:
- UI smoke gates passing,
- verified artifact identity and routing,
- aligned CSP and UI behavior,
- corrected API contract coverage,
- restored workflow writes with schema compatibility.
We’ll continue to treat “can a user complete the basics?” as a primary reliability signal, not an afterthought.